
The Predictive Edge: An Optimal AI-Powered Strategy for Major League Soccer Match Outcome Forecasting
Foundational Principles: The Intersection of AI, Analytics, and Soccer
The Theoretical Framework: Shifting from Human Intuition to AI
The pursuit of a competitive edge in sports betting requires a fundamental shift from traditional analysis based on intuition and limited statistics to a rigorous, data-driven methodology.
Predictive analytics, a discipline that uses statistics and modeling to forecast future outcomes by examining current and historical data patterns, provides the necessary framework for this evolution.
This methodology leverages advanced techniques from artificial intelligence (AI), including machine learning (ML) and deep learning (DL), to achieve a level of predictive accuracy unattainable through conventional methods.
AI-driven models offer a distinct advantage by processing and analyzing vast, complex datasets that are well beyond human capacity. These models are capable of identifying nuanced, non-linear patterns and correlations that traditional statistical models often fail to recognize, leading to more reliable and precise forecasts.
For online sports betting platforms, this translates directly to enhanced prediction accuracy, optimized risk management, and a significant competitive advantage. The core benefit of this approach lies in its ability to eliminate emotional bias and impulsive decision-making from the betting process itself, relying purely on data to inform strategy.
However, the objectivity of an algorithmic approach is not absolute. While AI systems do not experience human emotion, their predictive capabilities are entirely dependent on the data they are trained on and the design choices made by their creators. This introduces a subtle but significant form of bias.
For example, a model might learn to favor home teams not because of a quantifiable performance metric but because its historical training data contains a systemic referee bias in favor of the home side, such as awarding them more added time or fewer cards.
Therefore, a successful AI strategy must go beyond simply removing personal emotional bias; it must also actively detect and mitigate these algorithmic biases to ensure the integrity and fairness of its predictions.
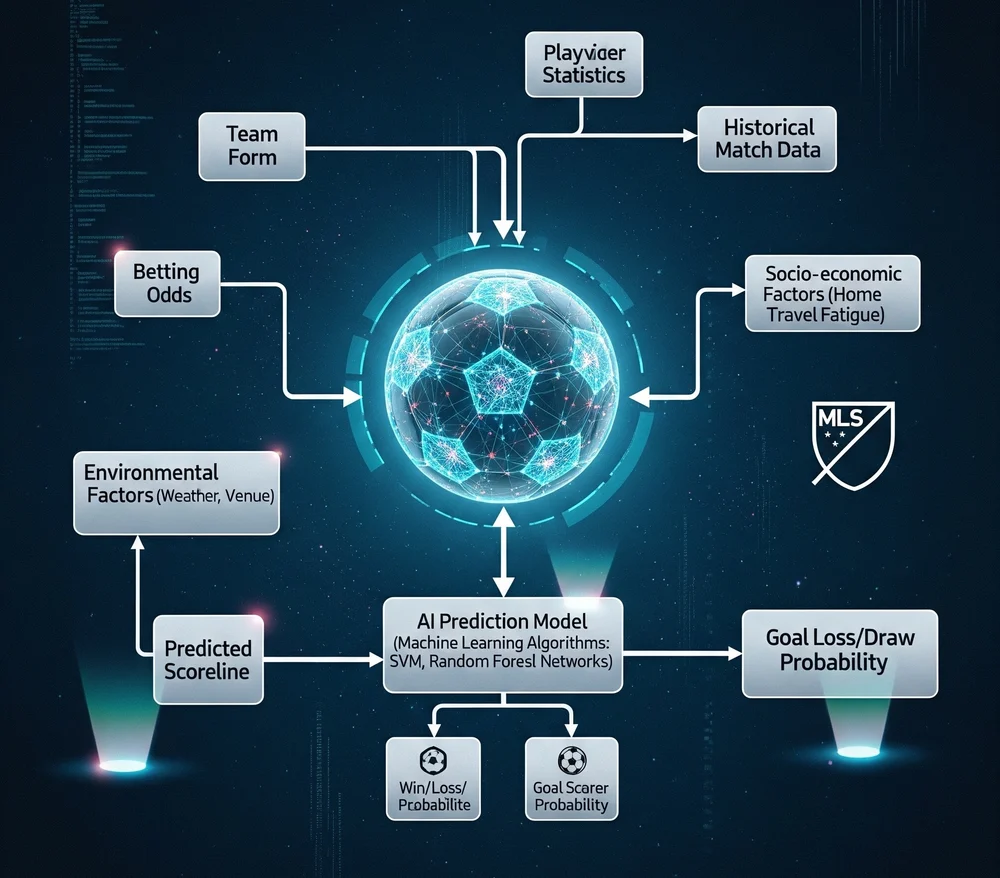
MLS as a Unique Predictive Challenge: Analysis of League-Specific Factors
Major League Soccer (MLS) presents a unique and compelling domain for predictive modeling. A generic soccer model, calibrated on data from European leagues, would fail to capture the nuances of MLS’s distinct structure and rules. A high-performance strategy must account for league-specific factors that profoundly influence match outcomes, including roster construction, travel, and postseason format.
The MLS salary cap is not a hard limit; it is a “soft” cap with several notable loopholes, including Designated Players (DPs), U22 Initiative players, and Targeted Allocation Money (TAM) players. Designated Players, in particular, can receive salaries that far exceed the maximum salary budget charge, making them a substantial financial investment for clubs.
The availability of these high-value players has a direct and quantifiable impact on a franchise’s performance and league standing. Traditional metrics, such as total team salary, are inadequate for capturing this dynamic.
A more robust predictive feature would be the “wage waste” caused by DP injuries or a metric for the total number of matches missed by a team’s designated players. This variable directly quantifies a team’s ability to leverage its most significant financial assets, which correlates strongly with on-field success.
Another critical factor is the extensive travel schedule unique to MLS, which covers vast distances across multiple time zones. Research indicates a significant physiological disadvantage for East Coast teams traveling west, where they win only 25% of their games, while West Coast teams traveling east win 52% of theirs.
The effect of jet lag, which can desynchronize internal circadian clocks, is particularly pronounced after eastward travel and can nullify the traditional home-field advantage. This suggests that a successful predictive model must incorporate variables that account for travel direction and the number of time zones crossed to accurately model player fatigue and its effect on performance.
A Taxonomy of Predictive Models: From Classics to Cutting-Edge
An effective AI-powered betting strategy for soccer must employ a hybrid approach that integrates various modeling techniques, from established statistical methods to cutting-edge machine learning algorithms.
- Statistical Models: The Poisson distribution model is a well-established probability model for predicting the number of goals scored by each team in a match. This model integrates factors such as offensive and defensive strengths, team form, and home-ground advantage. Another classic method is the ELO rating system, which was originally developed for chess but has been adapted to soccer to reflect a team’s strength based on past performance.
- Machine Learning Models: Machine learning models are widely used for their ability to identify patterns in large datasets. For binary classification problems like predicting a Win/Loss outcome, a simple but effective baseline is logistic regression. For more complex, multi-variate problems, ensemble methods are superior. A Random Forest model builds multiple decision trees and combines their results to improve accuracy and reduce overfitting, while gradient boosting algorithms like XGBoost and LightGBM iteratively correct errors from previous predictions.
- Deep Learning Models: Deep learning models, which use neural networks, are particularly adept at processing high-dimensional and unstructured data such as sequential match events, visual data, and text-based information from social media. Long Short-Term Memory (LSTM) networks are especially useful for time-series data, such as a team’s performance over a season. Hybrid models, which combine ML algorithms for structured data with deep learning for unstructured data, can enhance overall predictive accuracy.
A sophisticated predictive approach involves combining the strengths of these models. For example, a powerful strategy involves using a regression model to first predict a team’s Expected Goals (xG) total for a match. The xG metric quantifies the quality of scoring chances based on factors like shot location, angle, and shot type.
A Gradient Boosted Model (GBM) is a suitable choice for this task, as it can learn from a dataset of thousands of past shots and goals. The predicted xG total can then be used as the input for a Poisson distribution to determine the probability of each final scoreline, providing a more robust and granular prediction than a traditional Poisson model.
The Data Ecosystem: Fueling the Predictive Engine
Comprehensive Data Sourcing & Pipeline Architecture
The foundation of a high-performance AI betting strategy is a robust data ecosystem. This system must be designed as a real-time Extract, Transform, Load (ETL) pipeline that automates the collection, processing, and storage of data from multiple sources. The speed and reliability of this pipeline are paramount for gaining a competitive edge, especially in the context of live betting.
A crucial strategic distinction must be made between data sources. The lowest latency, most reliable data comes from official league partners like Genius Sports, which provide ultra-low latency data feeds sourced directly from stadiums. These feeds are significantly faster than TV broadcasts, which can be delayed by as much as 10 seconds. A real-time system built on these feeds can achieve a state of “latency arbitrage” by processing and acting on an in-game event—such as a key injury or a red card—milliseconds before a sportsbook has adjusted its odds. For live betting, which accounts for a significant portion of sports betting revenue, this speed is a competitive necessity, not a luxury.
While official APIs are the gold standard, supplementary data can be sourced through other means. Services like MySportsFeeds offer more accessible data, while web scraping can be used to gather historical odds, player metrics, and other data from betting websites like Bet365 and FanDuel. However, a web scraping strategy must be carefully managed to adhere to website terms of service and avoid overloading servers.
The entire data pipeline should be built on a scalable, cloud-based architecture using services like AWS Glue or Amazon SageMaker to handle the massive volume of data. This ensures that the system can process and analyze data at scale, from player tracking data that captures over 3 terabytes of information per game to traditional box scores.
Feature Engineering: Quantifying the Unquantifiable
The true value of a predictive model is determined by its features. This process, known as feature engineering, involves transforming raw data into powerful, meaningful variables.
Team & Player Performance Metrics
Beyond simple metrics like goals and assists, a competitive model relies on advanced, context-aware variables. A primary example is Expected Goals (xG), which measures the quality of a shot based on factors like distance, angle, and the type of play. An AI model can calculate a more sophisticated xG value for a shot by incorporating not only the shot’s characteristics but also the two actions that preceded it. This provides a granular measure of offensive performance that can be used to assess whether a team is overperforming or underperforming relative to the quality of its chances.
Player Availability & Fatigue Modeling
A team’s performance is directly tied to the health and availability of its key players. A predictive model must account for injuries and suspensions, which have a dramatic impact on match outcomes. More nuanced is the modeling of player fatigue, which can be derived from the travel schedule. By tracking travel direction and the number of time zones crossed, the model can quantify the physiological disadvantage that a team faces and incorporate this as a predictive feature. Similarly, the disciplinary record of players, such as accumulated yellow cards, can be used to predict future suspensions and a player’s potential absence from a match.
External & Contextual Factors
External factors, which are often overlooked, can provide a significant competitive edge. Referee tendencies, for example, are not random; they are subject to subconscious biases that can be modeled and predicted. Referees may be more lenient toward the home team, a bias that can be amplified by a large crowd or a stadium where supporters are close to the pitch. A sophisticated model should move beyond a simple home-field advantage variable and instead create a composite “referee bias” score based on the specific official assigned to the game, their historical disciplinary record, and the stadium’s architectural conditions. This score can then be a powerful input feature, particularly for prop bets on cards or penalties.
Financial & Roster Variables
A truly advanced model must account for the unique financial structure of MLS. Designated Players (DPs) are a team’s most valuable asset, and their presence—or absence—can be a primary determinant of a team’s success. The model should quantify this by analyzing the impact of “wage waste,” which measures the cost of a player’s salary during the time they are out with an injury. This variable provides a more granular understanding of a team’s financial efficiency and its ability to capitalize on its high-value investments. Data from sources like the MLS Players Association Salary Guide can be used to gather this information.
A comprehensive predictive system requires a structured approach to data management and feature engineering. The following table provides a blueprint for the key features to be incorporated into an MLS predictive model.

MLS Predictive Model Feature Matrix
| Feature Category | Specific Features | Description & Preprocessing | |
|---|---|---|---|
| Team Performance | Goals For/Against, Shots on Target, Possession % | Basic aggregate statistics. Requires cleaning and normalization. | |
| Advanced Metrics | Expected Goals (xG), Expected Assists (xA) | Derived from shot/pass data; requires a separate, robust sub-model (e.g., GBM) trained on location, angle, etc. | |
| Player-Level | Player Fitness & Availability | Binary flag for injury/suspension. Tracked via medical APIs or public sources. | |
| Travel & Fatigue | Travel Direction, Time Zones Crossed, Rest Days | Quantifiable numerical features derived from the travel schedule. | |
| Referee Tendencies | Referee’s Historical Average Cards/Game | A numerical score based on the specific referee’s past behavior. Can be adjusted for crowd bias. | |
| Financial/Roster | DP matches missed, “Wage Waste” | Calculated by tracking the availability of Designated Players and their salary data. | |
| Contextual | Weather Conditions, Field Conditions | Categorical or numerical data (e.g., WBGT temperature). |
The Predictive Core: Model Selection, Training, and Validation
Algorithm Selection and Justification
The choice of algorithm is dependent on the specific prediction task. No single model is optimal for all scenarios, and a hybrid approach is typically the most effective.
- Match Outcome Classification (Win/Loss/Draw): For this multi-class classification problem, ensemble methods are recommended. Gradient Boosting algorithms (e.g., XGBoost, LightGBM) or Random Forest models are highly effective. Gradient Boosting is known for its high accuracy by correcting errors from prior iterations , while Random Forest is praised for its ability to handle complex datasets and reduce overfitting.
- Specific Scoreline Prediction: For forecasting the number of goals scored by each team, a regression-based model is more appropriate. A synergistic approach using a Poisson-based model, where the input is a team’s predicted Expected Goals (xG) rather than a simple goal average, provides a powerful and robust framework for this task.
- Live Event Forecasting: Predicting in-game events and momentum shifts, which are time-dependent, requires models capable of handling sequential data. Deep learning models like Long Short-Term Memory (LSTM) networks or Temporal Fusion Transformers (TFT) are well-suited for this.
The following table provides a comparative analysis of the core algorithms.
Comparative Analysis of Core Predictive Algorithms
| Algorithm | Use Case | Strengths | Weaknesses |
|---|---|---|---|
| Logistic Regression | Binary Classification (Win/Loss) | Simple, highly interpretable, good baseline model. | Fails to capture complex, non-linear relationships. |
| Random Forest | Multi-class Classification, Regression | Manages complex datasets, reduces overfitting, handles feature interactions. | Can be a “black box” (less interpretable) and computationally intensive. |
| Gradient Boosting | Classification, Regression | Extremely high accuracy, excellent for complex patterns. | Prone to overfitting if not tuned properly, requires careful hyperparameter tuning. |
| Poisson Model | Count Regression (Goal Count) | Simple, effective for discrete count data. | Assumes independence of events; improved by using xG as an input. |
| LSTM Networks | Time-Series Forecasting | Captures temporal dependencies and patterns in sequential data. | Requires large datasets and is computationally expensive to train. |
A Step-by-Step Model Development Process
A robust model development process is essential for producing reliable predictions. This process should follow a professional data mining framework like CRISP-DM, ensuring that all steps are systematically executed.
- Data Splitting: The dataset should be rigorously split into training, validation, and testing sets, typically in a 70/15/15 ratio, to ensure the model can generalize to unseen data.
- Model Training: The selected algorithms are trained on the prepared data, a process that requires identifying suitable datasets, transforming the data, and tuning hyperparameters.
- Validation & Evaluation: The model’s performance must be evaluated using appropriate metrics. For soccer, the Ranked Probability Score (RPS) is a superior metric to simple accuracy or Root Mean Squared Error (RMSE). RPS provides a more holistic assessment by considering the ordinal nature of outcomes, recognizing that a prediction of a draw is more accurate than an away loss if the true outcome was a home win. Relying on RMSE, which penalizes large errors disproportionately, can incentivize a model to make “safe” predictions like a 1-1 draw, which does not accurately reflect true merit.
- Backtesting: The final, most critical step is to backtest the model’s predictions against historical odds from bookmakers. This process reveals whether the model’s predictions would have generated a profit over a long period by identifying value bets.
Strategic Application: Gaining a Competitive Edge
The Principle of Value Betting
A predictive model is a tool, but a successful betting strategy is a financial discipline. The core principle of a profitable strategy is value betting. This means identifying a discrepancy where the model’s calculated probability for an outcome is higher than the implied probability from the bookmaker’s odds. The relationship is defined by the formula: 1/model probability > bookmaker odds. The goal is not to predict the outcome with 100% accuracy, but to find situations where the market has undervalued a particular outcome. This principle can be applied to various markets, from over/under goal totals based on a team’s combined xG, to prop bets on specific player events.
The Live Betting Imperative
Live betting is a critical component of a competitive strategy, as it offers the opportunity to capitalize on in-game events and momentum shifts. An AI system can process real-time data from low-latency feeds up to 1,000 times faster than a human, enabling near-instant analysis of game stats, player status, and environmental factors. This allows a bettor to exploit the critical time gap between an event occurring on the field and the odds being adjusted by the sportsbook, a phenomenon known as latency arbitrage. The system can use an in-game xG model to track momentum shifts, providing a quantitative basis for a new wager.
The following table provides a strategic playbook for real-time betting by detailing specific in-game events and their corresponding impact on live odds and model predictions.
In-Play Event Impact Analysis & Odds Response
| In-Game Event | Impact on Match Dynamics | Model Response & Action |
|---|---|---|
| Red Card for Key Player | Immediate numerical and tactical disadvantage for the penalized team. Forces a more defensive mindset. | Drastically lowers the win probability of the penalized team. Triggers a value alert for the opposing team’s win or a prop bet on under goals for the short-handed team. |
| Unexpected Early Goal | Shifts the momentum and forces the trailing team to change its strategy. Can lead to a more open game. | Updates live win probabilities and xG projections. Identifies opportunities on over goals or for the trailing team to mount a comeback, especially if their pre-game xG was high. |
| Injury to High-Value DP | Significant loss of offensive or defensive output. Can be a major disruption to team cohesion. | Instantly recalibrates player-level and team-level projections based on the absence of the DP. Triggers a new value assessment for the remaining minutes. |
| Extreme Weather Change | Can lead to more fouls and less fluid gameplay. Wet/slippery pitches increase physical challenges. | Updates the model’s contextual variables. Triggers value alerts on prop bets related to disciplinary cards (over cards) or total shots. |
Prop Betting & Niche Markets
The greatest competitive edge often exists in niche markets where the bookmakers’ models are less efficient. Prop bets, which focus on granular, in-game events rather than the final match outcome, are a prime example. Examples of profitable prop bets in soccer include “Anytime Goal Scorer” or “Total Shots on Target”. A system can generate powerful predictions for these markets by leveraging the detailed feature engineering described previously, such as a player’s xG per 90 minutes or a referee’s historical disciplinary point average. It is important to note the legal and ethical risks associated with these markets, as they are sometimes associated with illegal activities like spot-fixing.

Operationalizing the System: Deployment & Management
A Blueprint for a Real-Time AI Platform
A predictive model remains a research project until it is deployed in a robust, automated system. For a competitive AI betting strategy, real-time inference is a non-negotiable requirement. In contrast to batch inference, which processes data at scheduled intervals, real-time inference executes predictions on incoming data with minimal latency, providing immediate responses to events as they unfold. This system can be architected with a REST endpoint to serve predictions, and a cloud-based service like Amazon SageMaker or Google Vertex AI can provide the scalable and cost-effective infrastructure needed for training and deployment.
Automation and System Maintenance
A successful operational system requires continuous maintenance and a high degree of automation. The ETL pipeline must be automated to reduce manual effort and ensure that data is clean, consistent, and validated at every stage. Predictive models are not static; they degrade over time as the underlying data patterns change due to new team compositions, tactical shifts, and external factors. The system must continuously monitor its models’ performance using key metrics like F1 score. When a model’s performance degrades below a predetermined threshold, the system should be configured to automatically trigger a retraining process using the latest data, ensuring that the deployed model is always the best possible version.
Navigating Legal & Ethical Complexities
The landscape of online sports betting is governed by a patchwork of state-level laws. As of 2025, 38 states and the District of Columbia have legalized some form of sports betting, with 29 of those permitting online and mobile wagering. Any operational system must be designed to adhere strictly to the legal and regulatory frameworks of each jurisdiction in which it operates, including age requirements and any restrictions on specific bet types, such as collegiate prop bets.
Beyond the legal framework, there are significant ethical considerations. The use of closed, “black box” AI models can raise concerns about fairness and transparency, potentially eroding bettor trust. Furthermore, the system’s ability to personalize betting suggestions and identify high-confidence opportunities carries the risk of inadvertently fueling addictive behaviors. A responsible AI strategy must incorporate safeguards and adhere to responsible gambling principles, acknowledging that while the technology can enhance decision-making, it also requires careful navigation to ensure its use is fair and ethical.
Conclusion & Future Outlook
Synthesizing the Strategic Approach
An optimal AI-powered strategy for predicting MLS match outcomes is a complex, multi-faceted system that synthesizes a robust data pipeline, a hybrid modeling approach, nuanced feature engineering, and a value-based betting strategy. The process is a continuous loop of data collection, model training, and strategic application. The competitive edge is not found in a single secret algorithm but in the meticulous execution of each component: from building a low-latency data pipeline to quantifying variables like player fatigue and referee bias, and finally, to applying the principle of value betting to exploit market inefficiencies. Success is a function of a system’s ability to process information faster and more comprehensively than the market, removing human emotional bias and capitalizing on a rigorous, data-driven approach.
The Future of AI in Sports Betting
The future of AI in sports betting will be defined by an even greater emphasis on granular data. Emerging technologies will provide new, richer data streams. Biometric data from player wearables will allow for real-time analysis of fatigue and injury risk, while computer vision will analyze tactical shifts and player formations in real-time, providing an even more granular predictive edge than is currently possible. These advancements will further reduce the gap between an event’s occurrence and the market’s response, making a low-latency, automated system not just a competitive advantage but an essential requirement for success. The field will continue to evolve, demanding constant iteration, retraining, and adaptation to maintain a competitive edge.
 How Offshore Sportsbooks Differ from Regulated Betting Sites (And Which is Better?)
How Offshore Sportsbooks Differ from Regulated Betting Sites (And Which is Better?)
 How Crypto is Transforming the World of Sports Betting
How Crypto is Transforming the World of Sports Betting
 The Evolution of Live Betting in Europe: Technology Meets Tradition
The Evolution of Live Betting in Europe: Technology Meets Tradition
 Cross-Sport Player Comparisons
Cross-Sport Player Comparisons
 Master the Odds: Unconventional Strategies at Top Online Sportsbooks
Master the Odds: Unconventional Strategies at Top Online Sportsbooks
 What Influences Odds Movement? Inside Look at the Market Behind the Lines
What Influences Odds Movement? Inside Look at the Market Behind the Lines
 Why Regulations Around Sports Betting Are Changing Fast — And What It Means for You
Why Regulations Around Sports Betting Are Changing Fast — And What It Means for You
 Navigating South Korea’s Sports Betting Scene: A Guide to Safe and Enjoyable Wagering
Navigating South Korea’s Sports Betting Scene: A Guide to Safe and Enjoyable Wagering
 Is Sports Betting Legal in Your State? The 2025 U.S. Legal Landscape Explained
Is Sports Betting Legal in Your State? The 2025 U.S. Legal Landscape Explained
 Betting Without Breaking the Bank: How to Budget and Stick to It in Sports Gambling
Betting Without Breaking the Bank: How to Budget and Stick to It in Sports Gambling
 How Moneyline Betting Works?
How Moneyline Betting Works?
 AI Sports Betting : The Ultimate Guide to Algorithmic Edge, Responsible Wagering, and Future Trends in the US
AI Sports Betting : The Ultimate Guide to Algorithmic Edge, Responsible Wagering, and Future Trends in the US